 Предназначение Предназначение
Предназначение ПредназначениеSDK Pullenti Address предназначено для выделения из текстов адресов, заданных в свободной форме, их нормализации, привязки выделяемых адресов к объектам ГАР ФИАС, а также поиск по названиям, Guid и другим атрибутам объектов ГАР. Дополнительно реализован адресный индекс (Адрессарий), куда можно записывать адреса, которым система назначает уникальные числовые идентификаторы, совпадающие для эквивалентных адресов. Отдельно предлагается способ сохранения нормализованных адресов в реляционной СУБД, чтобы для поиска использовать только sql-запросы.
Продукт Non-Commercial Freeware & Commercial Software, то есть бесплатен для некоммерческого использования и небесплатен для коммерческого. Для некоммерческого варианта привязка ограничивается объектами 77-го региона (Москва), для коммерческого - объекты всех регионов России. Внимание! Индекс для 77 региона - не бесплатный вообще, как и само SDK, а только для некоммерческих проектов (образовательных, личных, благотворительных, стартапов и т.п. - госорганизации сюда не относятся).
Объекты ГАР берутся из xml-файлов выгрузки с сайта https://fias.nalog.ru/Frontend и преобразуются во внутренний индекс посредством специальной утилиты (входит в коммерческую версию). SDK Address работает с внутренним индексом, который представляет собой набор из файлов внутреннего формата, оптимизированного для поисковых задач. Тем самым обеспечивается независимость использующих SDK Address систем от внешних сервисов - работа идёт с файлами локальной папки. Само SDK для своей работы не требует никаких дополнительных установок или внешнего ПО, а ограничивается стандартными библиотеками используемого языка программирования.
SDK предлагает 2 основные функции обработки. Первая функция на вход получает текст одного адреса (например, из поля ввода), и разбирает его структуру, привязывая элементы к объектам ГАР. Вторая функция обрабатывает произвольные тексты, находя в них адреса, которые также разбираются на элементы, привязываемые к ГАР. В первой функции действуют более сложные алгоритмы, которые понимают сокращения, нижний регистр имён, пропуск ключевых слов и пр. Вторая функция ориентирована на другую задачу, поэтому и алгоритмы немного другие.
Помимо этого, SDK содержит ряд полезных функций по работе с объектами ГАР:
Хотя изначально в ГАР для объектов отсутствуют GPS-координаты, мы их туда добавляем как дополнительные параметры. Информация берётся из нескольких источников. На текущий момент покрытие около 64% для домов и 60% для земельных участков.
Независимо от наличия или отсутствия ГАР, в SDK есть адресный индекс, названный Адрессарием. Его задача - сохранять внутри себя адреса, отождествляя эквивалентные с точностью до вариации написания, присваивая им числовые идентификаторы. Внешеняя система может использовать данную возможность для "уникализации" своих адресов, то есть присваивая через Адрессарий идентификаторы своим адресам. Адрессарий - это набор файлов проприетарного формата в одной директории. Одновременно можно работать с любым количеством Адрессариев.
Для сохранения нормализованных адресов в реляционной СУБД предлагается такая структура колонок и класс AddressDbRecord для их заполнения, что многие поисковые операции могут выполняться через SQL-запросы (в след. версии добавим соответствующий генератор sql).
SDK представлено функционально эквивалентным кодом на различных языках программирования: C#, Java, Python и Javascript. Исходный код вместе с этой документацией генерируется автоматически из исходного кода C# с помощью специально разработанного конвертера UniSharping. SDK работает на всех операционных системах и платформах, где поддержаны вышеуказанные языки. Свежую версию SDK можно скачать с сайта Garfias. Там же на сайте выкладываются свежие версии индекса для 77 региона.
Есть возможность не только обрабатывать адреса внутри своего приложения, но и отправлять адреса вовне на обработку серверу, который запускается в любом месте локальной сети (или на том же компьютере) и взаимодействует с SDK по http-протоколу. Обработка получается эквивалентной, но для Python или Javascript может оказаться существенно быстрее. Болеее того, для такого случая можно использовать усечённую версию SDK Pullenti Address (client version), которая содержит только адресные классы и взаимодействие с сервером.
Коммерческая версияВ коммерческую версию входит конвертер, который преобразует xml-файлы ГАР ФИАС с сайта Налоговой в файлы внутреннего формата (индекс), с которыми работает SDK. Преобразование это довольно трудоёмкое и в общей сложности занимает около суток. Поэтому мы сами делаем такое преобразование раз в 2-3 месяца и выкладываем готовый индекс для коммерческих пользователей. Однако пользователи могут сами делать это преобразование с любой периодичностью.
Отметим здесь, что SDK нормализует адреса без всякого индекса, однако наличие индекса улучшает качество нормализации. Также привязка или непривязка к существующим объектам ГАР могут служить критерием качества как самого адреса, так и процесса его разбора.
Подключение SDK в C#Для использования SDK нужно добавить в своё решение (solution) проект Address.Net.csproj для .NET Framework 4+ или Address.Core.csproj для .NET Core 3+ в зависимости от платформы, а в своём конечном проекте поставить ссылку на данный проект.
Для демо-примера необходимо скачать с сайта Pullenti архив Gar77.zip с индексом, распаковать его в папку Bin\Debug\Gar77 для Framework или Bin\Debug\netcoreapp2.0\Gar77 для Core.
Быстрый стартОсновным является статический класс AddressService, содержащий ключевые функции. В самом начале работы необходимо вызвать метод инициализации Initialize и указать папку с индексом ГАР методом SetGarIndexPath. Только после этого SDK готово к работе (в многопоточном режиме). Отметим, что если ГАР-индекс не указать, то всё будет работать, но без привязки выделяемых из текста адресов к объектам ГАР.
AddressService.Initialize();
AddressService.SetGarIndexPath("../Gar77");
В случае, если обработка производится через сервер (см. далее раздел), то вместо индекса нужно указать url-адрес сервера, и тогда все функции будут выполняться через запросы к нему. В этом случае можно использовать урезанную версию SDK (Client version).
if(!AddressService.SetServerConnection("http://localhost:1234")) // throw error
Анализ текста производится двумя методами: ProcessText и ProcessSingleAddressText.
В первом случае анализу подлежит любой текст с произвольным количеством адресов. Например, договор. Функция ProcessText ищет все адреса и возвращает список найденных объектов типа TextAddress, каждый соответствует одному найденному адресу. Этот адрес содержит список элементов адреса Items типа AddrObject, которые и привязываются к ГАР-объектам через их список Gars (список потому, что в принципе возможны несколько подходящих объектов ГАР).
List<TextAddress> addrs = AddressService.ProcessText(text, null);
foreach (var addr in addrs)
{
Console.WriteLine("Address: {0}", addr.GetFullPath(", "));
/// детализируем элементы адреса
foreach (AddrObject item in addr.Items)
{
Console.WriteLine(" {0}: {1}", item.Level, item.ToString());
if (item.Gars.Count > 0)
/// привязанных объектов ГАР в принципе может быть несколько
foreach (var gar in item.Gars)
Console.WriteLine(" Gar: {0} ({1})", gar.ToString(), gar.Guid);
}
}
Функция ProcessSingleAddressText предназначена для обработки текста, который заведомо содержит один адрес в свободном виде, и ничего кроме. Например, текст из поля ввода адреса. Вместо списка адресов, функция всегда возвращает один адрес TextAddress. Даже если адрес не выделен вообще, то список элементов Items будет пустым. Вычисляется коэффициент качества выделения Coef: значение 100 соответствует идеальному качеству, когда в тексте отсутствуют лишние символы (неизвестные конструкции) и все элементы однозначно привязались к ГАР-объектам.
text = "Москва, ул. 16-я Парковая д.2 кв.3 и какой-то мусор";
TextAddress saddr = AddressService.ProcessSingleAddressText(text, null);
Console.WriteLine("\nAnalyze single address: {0}", text);
Console.WriteLine("Coefficient: {0}", saddr.Coef);
if (saddr.ErrorMessage != null)
Console.WriteLine("Message: {0}", saddr.ErrorMessage);
foreach (var item in saddr.Items)
{
Console.Write("Item: {0}", item.ToString());
if (item.Gars.Count > 0)
foreach (var gar in item.Gars)
Console.Write(" (Gar: {0}, GUID={1})", gar.ToString(), gar.Guid);
Console.WriteLine("");
}
У обработки ProcessSingleAddressText есть большое преимущество по сравнению с результатом через ProcessText. Происходит более точный и качественный анализ в случае ошибок, сокращений, пропуска ключевых слов, использования нижнего регистра и т.п. Например, Ряз.обл,рязанский, рязань, пужкина,18 во втором случае обработает правильно, а в первом не поймёт никакой из элементов этого адреса. Но если нужно выделять адреса из произвольных текстов, то второй способ не сработает в отличие от первого.
Метод GetChildrenObjects возвращает список дочерних ГАР-объектов по идентификатору родительского объекта (если null, то возвращает список самого верхнего уровня, то есть регионы). Метод GetObject вернёт ГАР-объект по его идентификатору, что пригодится для движения по иерархии вверх.
Поиск по тексту наименований ГАР-объектов и по реквизитам производится через функцию SearchObjects, параметры поиска оформляются классом SearchParams, результатом является класс SearchResult с ограниченным списком найденных объектов (их в принципе может быть много) и общим количеством подходящих объектов.
Если в тексте адреса не задан населённый пункт, а только улица с домами, или задан населённый пункт без региона, то можно вторым параметром у этих функций ProcessTextParams передать информацию о дефолтовых объектах или регионах:
Модель адресаАдрес состоит из нескольких элементов, упорядоченных по уровню в порядке убывания. На верхнем уровне находятся страны и регионы, на нижнем - дома и помещения. ГАР предлагает свою систему уровней, которая оформляется перечислением GarLevel и взята за основу уровней AddrLevel для адресов из текста. Приведём соотношение этих уровней и их описание.
| Адресный уровень AddrLevel | ГАР уровень GarLevel | Описание |
|---|---|---|
| Country | Нет | Страна |
| RegionCity | Region | Город регионального значения (Москва, Санкт-Петербург, Севастополь) |
| RegionArea | Регион (область, республика, край) | |
| District | AdminArea | Административный район |
| MunicipalArea | Муниципальный район | |
| Settlement | Settlement | Сельское/городское поселение |
| City | City | Город |
| CityDistrict | District | Район города (устарело в ГАР) |
| Locality | Locality | Населенный пункт |
| Territory | Area | Элемент планировочной структуры (кварталы, территории) |
| Street | Street | Элемент улично-дорожной сети (улицы) |
| Plot | Plot | Земельный участок |
| Building | Building | Здание (сооружение) |
| Apartment | Room | Помещение, квартира |
| Room | Комната | |
| Carplace | Машино-место |
В зависимости от уровня, элемент может иметь свой набор атрибутов. Базовый класс наборов атрибутов - пустой. Наследными являются классы AreaAttributes, HouseAttributes и RoomAttributes. Общая диаграмма представлена на рисунке.
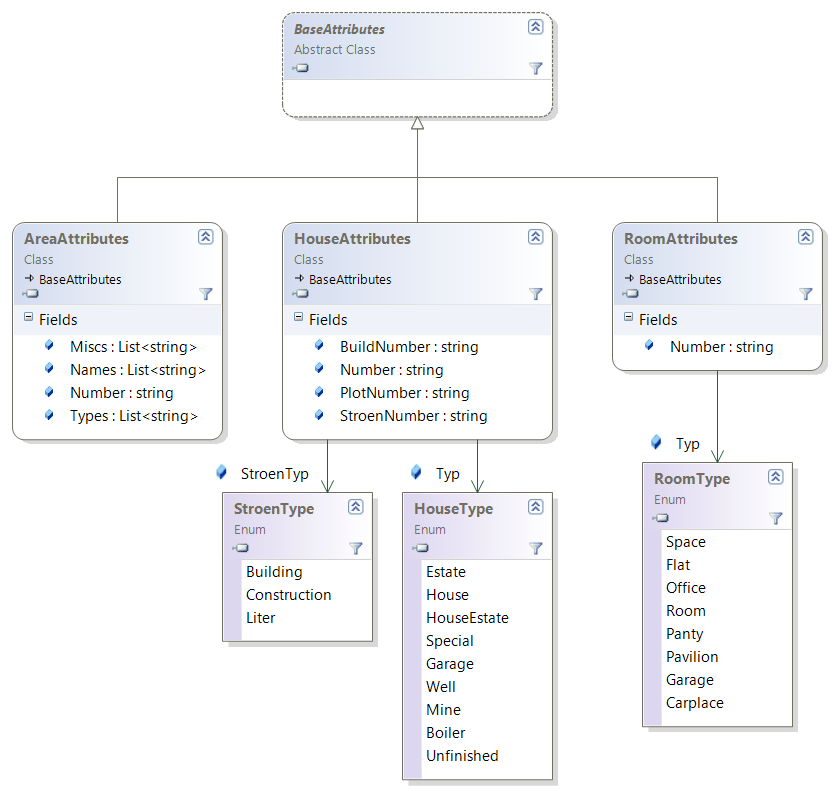
Атрибуты объектов уровней с верхнего до улиц оформляются классом AreaAttributes. Они имеют один или несколько типов Types, несколько имён Names (в том числе могут их и не иметь), а также может быть номер Number. Могут быть ещё дополнительные строки Miscs, в которые помещаются имена, атрибуты персон (фамилия попадает в Names) и другие второстепенные значения.
Для уровней "земельный участок" и "здание" - класс HouseAttributes. Здание в общем случае имеет номер Number, корпус BuildNumber и строение StroenNumber. Дом и строение имеют дополнительные типы Typ и StroenTyp. У участка есть номер PlotNumber. Но участок может иметь и атрибуты здания, если он не имеет своего номера, а связан с расположенным на нём зданием (уч. дома №5).
Для помещений и комнат класс для атрибутов RoomAttributes содержит номер Number, тип Typ и, возможно, дополнительный атрибут Misc.
Объекты ГАРОбъекты ГАР реализованы классом GarObject, имеющим поля:
У каждого ГАР-объекта есть словарь, в котором находятся различные реквизиты типа почтового индекса, кадастрового номера, GPS-координат и др. - список типов параметров определятся перечислением GarParam. Получить такой словарь можно фунцией GetParams, либо получить конкретный реквизит функцией GetParamValue.
Сейчас поддерживаются следующие параметры:
| Значение GarParam | Описание | Формат | Комментарий | |
|---|---|---|---|---|
| Guid | уникальный идентификатор | GUID | ||
| ObjectId | числовой внутренний идентификатор ГАР-объектов | число | ||
| KladrCode | код КЛАДР | число | тип 10 в ГАР | |
| PostIndex | почтовый индекс | 6 цифр | тип 5 в ГАР | |
| Okato | ОКАТО | цифры | тип 6 в ГАР | |
| Oktmo | ОКТМО | цифры | тип 7 в ГАР | |
| KadasterNumber | кадастровый номер | 4 группы цифр через двоеточия | тип 8 в ГАР | |
| ReesterNumber | реестровый номер | 4 группы цифр через двоеточия | тип 13 в ГАР | |
| GpsPoint | координаты GPS | Lat Lon | Внешний | |
| GpsRectangle | прямоугольная область GPS | LatMin-LatMax LonMin-LonMax | Внешний | |
| Floors | этажность объекта | число_этажей/число подвальных_этажей | Внешний | |
| Year | год постройки или ввода в эксплуатацию | год | Внешний |
Предвосхищаем вопрос: а почему нельзя было в качестве значений Id использовать значения Guid? Потому, что с ними очень неэффективно работать в условии, когда частой операцией является получение объекта по его Id, например, при построении иерархии вверх. Пришлось вводить внутренние Id для осуществления быстрого доступа. По ряду причин мы также не стали использовать числовой ObjectId. ВНИМАНИЕ! Внешним системам не следует привязываться к Id, так как в очередной версии индекса значения объектов вообще говоря изменяются - для внешней идентификации следует использовать Guid или ObjectId (который в принципе тоже может меняться в ГАР, но редко).
Объект по его идентификатору Id (не Guid и не ObjectId!) можно получить функцией GetObject, список дочерних объектов извлекается функцией GetChildrenObjects, передавая на вход идентификатор родителя или null для верхнего уровня иерархии (регионов). Это сделано намеренно, так как такое получение связано с обращением к индексу ГАР и, вообще говоря, требует некоторых вычислительных ресурсов.
Поиск ГАР-объектов производится функцией SearchObjects, на вход подаются параметры поиска, оформленные классом SearchParams, на выходе возвращается объект SearchResult:
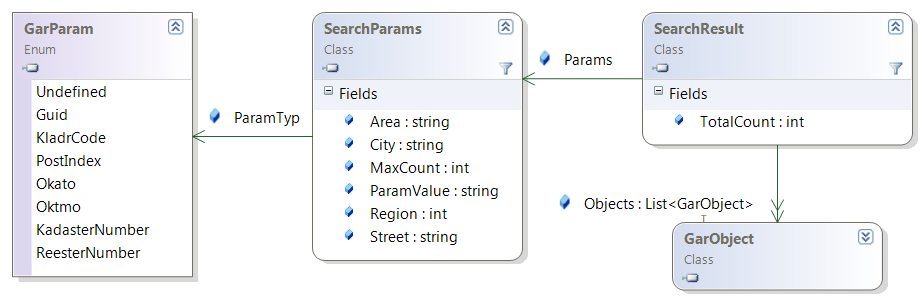
Возможны 3 вида поиска:
Адреса из текстаАдрес, выделяемый из текста, оформляется классом TextAddress. Он содержит список адресных элементов Items класса AddrObject, упорядоченный по убыванию уровня, а также ряд дополнительных атрибутов. Такие адреса формируются либо функцией ProcessText, возвращающей список TextAddress, либо функцией ProcessSingleAddressText, возвращающей один адрес.
Элемент адреса AddrObject имеет набор атрибутов Attrs - экземпляр от наследного класса от BaseAttributes, уровень Level и список привязанных ГАР-объектов Gars, которых в общем случае может быть несколько или вообще не быть. Взаимосвязь классов дана на диаграмме.
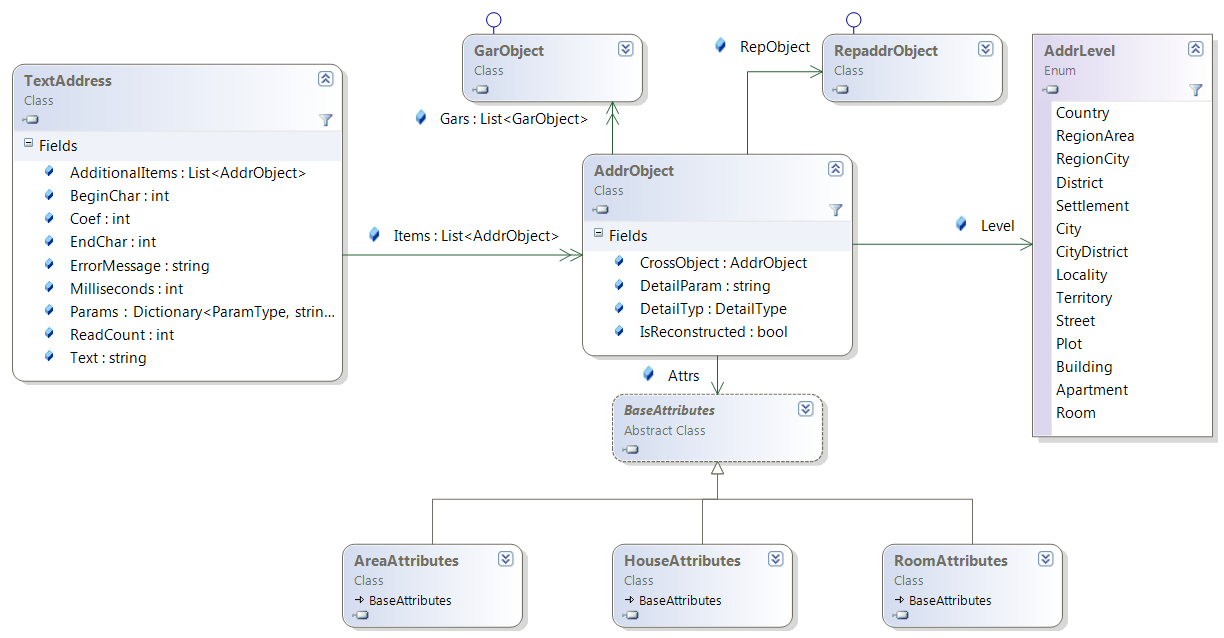
Класс адреса TextAddress содержит ещё и такие атрибуты:
Независимо от ГАР, у текстовых объектов AddrObject можно использовать функцию ToString() для получения нормализованного представления. Отметим, что это только один из нормальных вариантов, которого для практических задач может вполне хватить. Но функция ToString() выводит только текущий объект. Для нормального вывода всего адреса целиком можно вызвать GetFullPath, параметром задавая разделитель.
У объектов AddrObject есть ещё одно поле - ссылка на другой объект CrossObject, которым оформляются случаи задания объектов на пересечении улиц. Например, гор.Тула ул.Кауля/Р.Лозинского д.82/35. В этом случае объект для улицы оформляется для "ул.Рауля", а CrossObject - для "ул.Р.Лозинского", и каждый из них привязывается к своим объектам ГАР. Также и на уровне домов объект для "д.82" и CrossObject для "д.35" с привязкой к ГАР-объектам по своим улицам каждый.
Также бывают ситуации, когда в адресе указываются несколько домов или квартир, через запятую, союз и\или диапазоном. В этом случае в список Items попадает только первый из них, а остальные заносятся в список AdditionalItems. Например, "... дом 10 кв.1,2 и 3-6" в основной список попадёт квартира 1, а квартиры 2, 3, 4, 5 и 6 в дополнительный список, причём эти объекты также будут привязываться к ГАР.
В реальных адресах встречаются указатели относительно ориентиров, в которых задаётся направление и, возможно, расстояние. Для этого у AddrObject есть поле DetailTyp для типа DetailType и DetailParam для возможного параметра (обычно расстояние, которое приводится в метры). Значения типов:
Например, Московская область, Можайский район, примерно в 0,1 км по направлению на юг от ориентира середина д.Бараново для деревни Бараново оформит детализацию с типом South и значением "100м" (приводится в метры). Или Московская область, Шаховской район, сельское поселение Серединское, у д. Пахомово, кадастрового квартала 50:05:0040211 в западной части для квартала детализация типа West и значением "часть".
Адрес может содержать различные второстепенные элементы, не вписывающиеся в общую стройную модель. Например, этажи, генпланы, а/я и пр. Такие элементы записываются в словарь Params, ключом является перечисление ParamType, а значение записывается в строковом виде. Сейчас поддержаны такие типы элементов:
Коэффициент качестваУ TextAddress устанавливается Coef коэффициент качества, принимающий значение от 100 до 0, при этом 100 означает "идеальное выделение". Опишем здесь примерные принципы его формирования, что влияет на его уменьшение и что не влияет. Отметим, что даже если коэффициент = 100, всё-равно возможны комментарии в ErrorMessage.
На уменьшение этого коэффициента влияет следующее:
Координаты GPSКоординаты GPS отсутствуют среди параметров объектов ГАР, но в индексе Pullenti они добавлены к объектам ГАР. Возможны точка GPS и прямоугольник GPS (это не полигон, а именно прямоугольник, накрывающий полигон), которые можно получить функцией GetParamValue по следующему ключу:
Для работы с объектом GPS (точкой или прямоугольником) можно использовать класс GpsObject, в который можно переводить строковое представление этих параметров, подавая их на вход конструктору этого класса. В этом классе есть ряд полезных функций по вычислению площади, расстояния между объектами и т.п.
Не все объекты ГАР имеют GPS-координаты. В настоящее время их имеют около 64% домов и 60% участков в среднем по России. Этот процент зависит от региона, например, для Москвы эти значения 71% и 87%. Для улиц, населённых пунктов и т.п. если явные координаты отсутствовали, то они определяются через премоугольник GPS, накрывающий все координаты внутри лежащих объектов (если у них у самих есть GPS).
АдрессарийАдресный индекс (Адрессарий) предназначен для хранения адресов и отождествления похожих. Для работы с ним есть класс AddressRepository. После создания экземпляра, нужно вызвать функцию Open, передав параметром имя локальной папки (если не существует, то будет создана), в конце работы нужно вызвать Dispose.
Добавляются адреса функцией Add, где параметром является не текст адреса, а уже разобранный адрес TextAddress. Добавлению подлежат все его элементы AddrObject. При этом у добавляемых элементов AddrObject в случае успеха устанавливается RepObjectId идентификатор экземпляра репозиторного объекта RepaddrObject, который либо создаётся и добавляется в Адрессарий, либо берётся существующий в случае отождествления. Если нужно только искать существующие элементы без добавления, то используется функция Search.
Если поле RepObjectId у адресного элемента получилось 0, то по каким-то причинам адресный элемент не может быть добавлен. Например, при нарушении принципа иерархии - указана квартира без дома, для адреса "Москва, дом 10" дом не будет добавлен. Также объект самого верхнего уровня должен быть город, регион или страна, иначе это не считается полноценным адресом.
Замечание: мы не рекомендуем добавлять адреса с коэффициентом Coef меньше 80, так как качество таких адресов - сомнительное.
При добавлении некоторой порции адресов (500-1000) и в конце добавления нужно вызывать функцию Commit, чтобы несохранённые данные записались на диск. Если этого не сделать, то индекс может испортиться и не работать корректно. В конце загрузки большого количества адресов (сотен тысяч) не обязательно, но желательно вызвать Optimize, которая уменьшит общий объём файлов индекса и оптимизирует его для функций поиска.
Объект Адрессария представлен классом RepaddrObject. Он имеет:
Внутри Адрессария объекты образуют иерархию, но не жёсткую, так как в принципе объект иерархически может законно относиться к разным элементам. Например, в ГАР ФИАС подобное можно наблюдать из-за несовпадающей административной и муниципальной иерархий. В адресе могут какие-то второстепенные элементы опускать, или наоборот - вставлять. Поэтому у объекта может быть несколько потенциальных родительских объекта.
Для получения объекта по идентификатору используйте функцию GetObject(id), для списка дочерних элементов GetObjects.
А как связан Адрессарий с ГАР? Дело в том, что адрессарий для добавляемых элементов использует не только разные формы записи наименований, чтобы отождествлять с точностью до таких вариаций, но и Guid объектов ГАР, если таковая привязка имела место, то есть идентификатор ГАР используется как дополнительный вариант наименования. Это повышает качество привязки. Например, в случае переименования улицы её Guid-сохранится, хотя наименование изменится. Так что ГАР не обязателен, но желателен (для российских адресов).
ВНИМАНИЕ! В текущей реализации работа с экземпляром Адрессария однопоточная, то есть нельзя из разных потоков добавлять и из других искать. Если потребуется, в будущем поддержим многопоточность.
Индекс ГАРИсходные данные ГАР ФИАС выкладываются на сайте ФНС, и представляют собой zip-архив около 36Гб (280Гб после распаковки) с файлами формата xml, в которых и находится вся информация.
Для преобразования в индекс, используемый в SDK Address, разработана специальная утилита gar2pullenti.exe, преобразующая xml-файлы в несколько десятков файлов проприетарного формата, оптимизированного для решения поисковых задач. Эта утилита входит в коммерческую версию SDK. Поскольку процесс трансформации занимает около 11 часов (плюс несколько часов на скачивание архива и около часа на разархивирование), то планируется ежемесячное обновления преобразованного индекса ГАР, чтобы пользователи не тратили на это свои ресурсы. Полный индекс ГАР доступен для коммерческой версии, для бесплатной выкладывается индекс 77-го региона (Москва).
Утилита запускается в пакетном режиме и управляется следующими аргументами командной строки:
Например, если индекс планируется использовать только вплоть до улиц в поле ввода, то нет смысла грузить строения и помещения, на порядок увеличивающие размер индекса.
К сожалению, эти xml не содержат информацию о переименованиях населённых пунктов и улиц, однако там же на сайте ФНС на вкладке "Формат КЛАДР 4.0" есть данные, в которых эта инфомация есть! Рекомендуется скачать свежую версию архива base.7z, распаковать его и указать папку ключом -kladr утилите, и тогда старые наименования также будут добавлены в объекты и учитываться при привязке.
Работа без индекса ГАРА будет ли выделение адресов и их нормализация без индекса ГАР? Да, будет. Индекс ГАР не является необходимым для работы системы, и если его нет, то просто функцию AddressService.SetGarIndexPath(...) не надо вызывать - и всё будет работать.
Однако наличие индекса ГАР улучшает качество выделения, так как информация из него используется не только для привязки, но и для восполнения отсутствующих в тексте адреса уровней и разрешения различных неоднозначностей. Например, ... ул. Цветочная 1/10 здесь 1/10 может быть как дом с таким номером, так и "дом 1 кв. 10", что можно понять только при наличии соответствующей информации (если она есть в ГАР, разумеется). Или забывают указать населённый пункт, но при этом задают почтовый индекс. Или различные опечатки в названиях исправляются через правильные наименования ГАР.
Короче, довольно много случаев, когда ГАР помогает при распознавании улучшать качество, поэтому хотя без него можно обойтись, но качество в общем случае получится ниже.
Рекомендации по обработке. Внешний серверВыделяемые из текста адреса оформляются объектами TextAddress, содержащие суммарные коэффициенты качества Coef. В дальнейшую обработку адрес рекомендуется брать только если этот коэффициент больше некоторого порога, зависящего от конечной задачи. Мы рекомендуем игнорировать адреса с коэффициентом ниже 80.
Если нужно обрабатывать тексты, которые содержат только адреса (например, из полей ввода), то используйте функцию ProcessSingleAddressText. Примерная скорость обработки на компьютере средней мощности: 100-200 адресов в секунду при использовании SDK C# и Java.
Если у вас в файле много адресов в заранее известном структурированном виде (например, CSV-файл или текстовой файла с адресом в каждой строке), то нужно самим разбить текст на фрагменты с адресами и обрабатывать каждый через ProcessSingleAddressText, а не пытаться прогнать всё через ProcessText. Во втором случае адреса будут выделены, но качество может оказаться хуже, так как в первом случае используются дополнительные алгоритмы коррекции и анализа. ProcessText следует использовать только для неструктурированных текстов, в которых заранее неизвестны места расположения адресов, например, для Html-страниц или договоров.
Для SDK Python скорость раз в 20 ниже, но здесь поможет сервер Address.Server.dll, реализованный на .NET Core. Он запускается в локальной сети или на том же компьютере, а SDK взаимодействует с ним по TCP-IP. Если вызвать функцию SetServerConnection, подав на вход uri сервера (по умолчанию, http://localhost:2222), то все функции AddressService будут отрабатывать не через логику текущего приложения, а отправляться на сервер для обработки. Это может на порядок улучшить производительность. В данном случае вместо ProcessSingleAddressText лучше использовать ProcessSingleAddressTexts, обрабатывая адреса порциями по 200-300 штук. Кстати, при работе через сервер не нужно инициализировать Initialize.
Для SDK Javascript скорость раз в 5 ниже, чем для C# и Java, и здесь также можно использовать сервер для ускорения.
После обработки адреса мы получаем иерархический список его элементов в терминах уровней ГАР, с привязкой к ГАР-объектам или без. Эту информацию можно далее сохранять в свою БД, каким-то образом учитывая эту иерархию и отождествляя с уже существующими элементами, что тоже непростая задача. Порекомендуем использовать Адрессарий, который и предназначен для решения такой специфической задачи.
Если нужно быстро обработать адреса из какого-нибудь поля CSV-файла, то для пользователей Windows в стенде Address.Textdesk есть такая возможность на вкладке "Обработка CSV" (см. далее).
Минимальный SDK Pullenti Address (client version)Если производить обработку через сервер, то полноценный SDK в принципе не нужен, а нужны только функции взаимодействия с сервером и классы, которые представляют результат. Для этого можно использовать урезанную версию - SDK Pullenti Address (client version).
Она на порядок меньше основного SDK, так как не содержит огромной NER-части по выделению адресов, поддержку взаимодействия с адресным индексом, блока привязки к ГАР-объектов и пр.
Работа здесь абсолютно аналогична как и в основном SDK - через функции статического класса AddressService, но здесь нужно обязательно задать uri сервера функцией SetServerConnection, проверить доступность сервера можно функцией GetServerVersion. Все остальные функции аналогичны как в основном SDK, так что в программе пользователя ничего не придётся менять при переключении между этими SDK (кроме функции инициализации или задания адреса сервера).
Визуализация обработки (стенд)SDK Address в своём составе не содержит никаких средств визуализации, так как является кросс-платформенной и мультиязычной. Некоторая визуализация обработанных данных есть на сайте Pullenti Address в разделе Online-demo. Для пользователей Windows есть стенд, в котором можно провести анализ и получить результаты в наглядном виде, а также поработать с объектами ГАР.
Архив стенда Address.TestDesk нужно скачать с сайта, распаковать в директорию и запустить исполняемый файл Address.Testdesk.exe. Также нужно скачать и распаковать предлагаемый индекс gar77.zip, указав эту папку в стенде через кнопку "Открыть индекс". На вкладке "Индекс ГАР" выводится иерархия объектов, в правом окне отображаются реквизиты и параметры текущего объекта. Фактически это дерево реализовано через функцию GetChildrenObjects.

В поисковом окне слева фактически задаётся экземпляр SearchParams, поиск проводится через SearchObjects, а список GarObject выводится в таблице ниже, причём в первом столбце объект самого нижнего уровня, во втором - его родитель и т.д. Нажатие мышью на ячейке этой таблицы делает объект выделенным в дереве.
На вкладке "Обработка текста" демонстрируется функция ProcessText и визуализация результата:
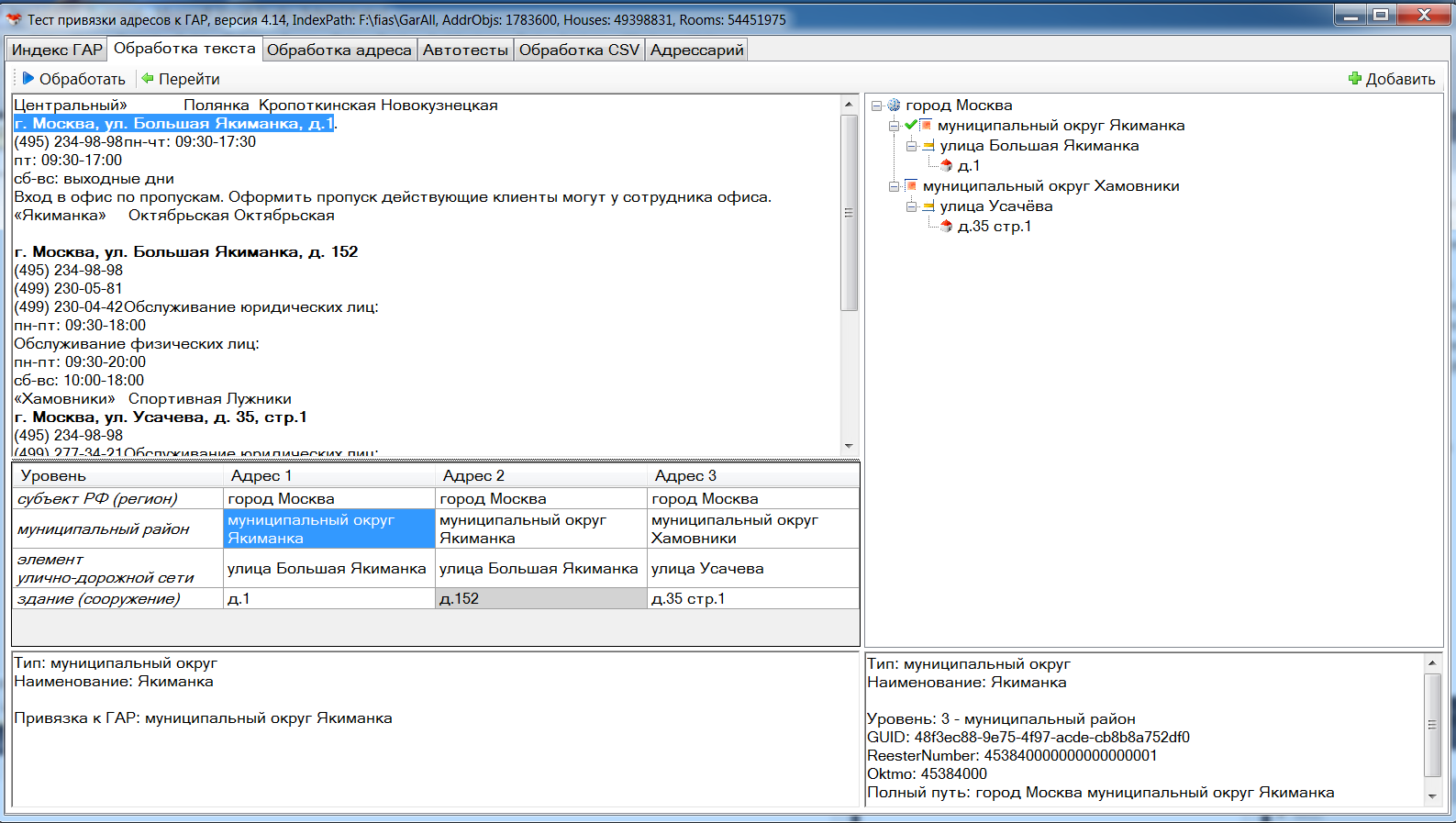
В левом верхнем окне задаётся текст, после нажатия на кнопку "Обработать" в таблице выводятся текстовые объекты AddrObject, в разрезе уровней ГАР (серым подсвечены непривязанный к ГАР элементы). Выделенные адреса выделяются жирным шрифтом в обработанном тексте. В правом окне выводятся те объекты ГАР, к которым привязались текстовые элементы (при этом добавляются и все ГАР-объекты вверх по иерархии, даже если они явно не присутствовали в тексте).
На вкладке "Обработка адреса" демонстрируется функция ProcessSingleAddressText и визуализация результата аналогично вкладке "Обработка текста", только выделяемый адрес всегда один и используются более мощные алгоритмы.
На вкладке "Обработка CSV" можно обработать множество адресов из CSV-файла и сохранить результат в CSV, добавив в него поля с новыми данными.
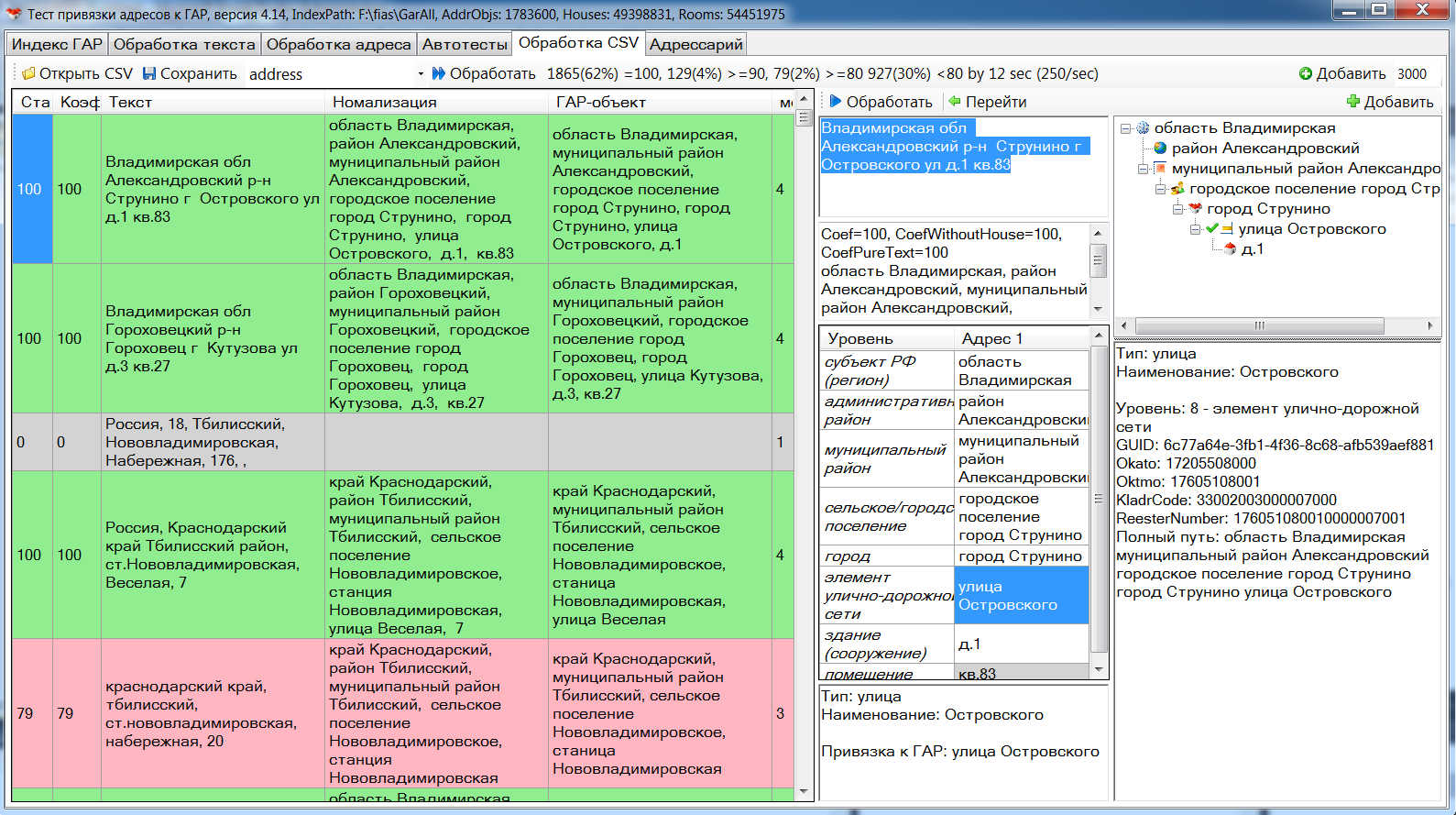
На вход стенд понимает CSV-файл с разделителями ';' в кодировке UTF-8 или Windows-1251. Это также может быть текстовой файл, у которого в каждой строке находится адрес и ничего кроме. Слишком много адресов стенд может не уместить в памяти, поэтому в файле не должно быть более нескольких сотен тысяч адресов. После загрузки файла в случае нескольких полей система пытается найти то, которое содержит адреса, и выводит это поле в выпадающем списке на панели. Если адреса содержит другое поле, то его нужно выбрать из списка. Кстати, xls и xlsx файлы можно преобразовать в CSV утилитой file2csv.exe, входящей в архив со стендом. В архив также добавлен файл demo77.csv с московскими адресами для демонстрации этого функционала.
Обработка производится по нажатию на кнопку "Обработать". Процесс можно прервать кнопкой "Стоп" рядом с бегущей строкой. На панели отображается статистика - сколько адресов имеют коэффициент 100, сколько от 90 до 99, сколько от 80 до 89 и все остальные. В таблице адреса с коэффициентом 100 выделяются зелёным фоном, сам коэффициент выводится в первой колонке. Нажатие на колонку приводит к сортировке по этому значению. Кнопкой "Убрать 100" можно убрать все зелёные адреса, оставив "плохие" (их можно сохранить в файл и отправить разработчику для совершенствования алгоритма).
Сохранить результат можно кнопкой "Сохранить", в результирующий файл попадут все поля из исходного файла, при этом к ним добавятся дополнительные поля:
Здесь если элемент некоторого уровня привязался к ГАР-объекту, то в первом поле выводится его (ГАР-объекта) текстовое представление, а во второе поле его GUID. Если привязались несколько объектов, то выводится только первый (случайно взятый). Если ни одного объекта не привязалось, то в первое поле выводится нормализованное значение этого текстового элемента, второе поле пустое. Если для уровня элемент отсутствует, то оба поля пустые.
Дефолтовые регионы можно задать на главной панели в соответствующем поле (несколько разделяются пробелом). Дефолтовый объект (город) устанавливается на вкладке "Индекс ГАР", либо задать его имя на главной панели вместо кодов регионов.
Соображения по нормализации и хранениюПроцедура нормализации - не однократная, а должна периодически повторяться. В идеале она должна повторяться на каждой новой версии ГАР, а также при смене (корректировке) алгоритма.
При реализации хранилища с результатами нормализации нужно учесть ряд факторов. Адрес - это не монолит, а набор адресных элементов (АЭ) разных уровней начиная от страны и заканчивая помещениями и машиноместами. В адресе некоторые уровни могут отсутствовать. На некоторых уровнях может быть сразу несколько разных АЭ одного уровня. Хранить у нормализованного АЭ можно (нужно) следующее:
Исходное поле адреса может содержать:
Для одного поля адреса в БД должно быть (и периодически пересчитываться):
Вариант представления нормализованных адресов в БДПусть имеется таблица БД с адресами, хранящимися в текстовом поле и которые нужно "нормализовать" (если адрес распределён по нескольким полям, то для обработки его можно собрать в одну строку, желательно разделяя запятыми). Результат обработки можно хранить как в той же таблице, добавив в неё новые поля, так и в новой таблице, сохраняя связи с записями исходной таблицы.
Здесь предлагается вариант таких новых полей со значениеми, кототый ориентируется на задачи поиска адресов по разным частям, отождествлении адресов и др., причём такие задачи должны решаться исключительно средствами SQL-запросов (select). Для этого предлагается использовать класс AddressDbRecord, экземпляр которого создаётся функцией CreateFromAddress, на вход которой поступает результат разбора одного адреса TextAddress. То есть берётся исходный текст адреса, нормализуется через ProcessSingleAddressText, а затем по полученному экземпляру TextAddress делается экземпляр AddressDbRecord, поля которого записываются в БД как результат нормализации.
Поля предлагаются такие (названия могут быть свои, понятное дело), значения описываются далее:
Поисковые мнемоники задаются для именованных объектов по их именам, причём тип отбрасывается. Поисковые мнемоники составляются таким образом, чтобы в случае поиска по ним использовать в SQL условиях точные сравнения, а не менее производительные операторы like. Исходя из этого, при составлении таких мнемоник применяются следующие правила преобразования:
Например, "Малый Конюшенный переулок" -> "КОНЮШЕН МАЛ", "пос. им. Юрия Гагарина" -> "ГАГАРИН", "территория фабрики 8 Марта" -> "МАРТ 8", "Пенсильванско-Иллинойский штат" => "ИЛИНОЙСК ПЕНСИЛВАНСК".
У домов довольно сложная система, состоящая в общем случае из нескольких номеров (до трёх), относящихся к домам, корпусам и строениям (литерам), при этом каждый номер может быть буквенно-цифровым или состоять из нескольких цифр, разделённых дробью. Причём такая комбинация может быть записана сколь угодно причудливо. Например, эквивалентными будут: “д.10/1A” = “д.10/1 корп А” = “д.10/1 лит.А” = “д.10 корп. 1 стр. А” и т.д. Для универсальности предлагаем абстрагироваться от разных корпусов, строений и литер, а использовать последовательность элементарных элементов, каждый из которых либо число, либо буквенная комбинация (бывает в номерах несколько букв подряд, например, “дом 10АБ”). Комбинация начинается с обобщённого типа:
Далее через пробел идут элементы. Например, “д.10/1A” => Д10 1 А (как видно, все вышеуказанные варианты дадут такую же поисковую мнемонику), “корп. 567Б” => К567 Б, “уч.25” => У25, “влад. б\н” => Д
Для помещений нумерация подобна домам, но проще, так как в принципе состоит из одного номера (хотя и содержащего цифры и буквы, дроби и дефисы). Мнемоника также начинается с обобщённого типа:
Далее также идут элементы номера через пробел.
Для объектов уровней до 5-го (населённый пункт) вообще не имеет смысла учитывать типы, так как в реальных адресах постоянно путают сёла, поселения, посёлки и пр. друг с другом, с районами аналогично, к тому же есть несколько иерархий (муниципальная и административная), в которой объекты называются обычно одинаково, но имеют разные типы. А вот для территорий и улиц типы учитывать необходимо, и они выносятся в отдельные свои поля. Особенность здесь в том, что это может быть не один тип, поэтому строка составляется из них всех, разделённых знаком '|', а в SQL приходится использовать либо like '%[...]%' по этому полю, либо делать это поле массивом и условие типа "and 'значение' = any (поле)". Например, "улица Бунинская аллея" -> "АЛЛЕЯ|УЛИЦА" (а "БУНИНСК" попадает в поисковую мнемонику по имени), "территория ГСК "Колесо" №32" -> "ГСК|ГАРАЖИ" (здесь "гаражи" добавляется специально, так как только на ГСК ориентировтаться нельзя, ибо написания этих форм собственности может быть различное).
Насчёт полей с GUID объектов ГАР - в них может храниться не один, а вообще говоря от 0 до нескольких идентификаторов, и если их несколько, то они разделяются '|'. В этом случае поиск по ним идёт либо через like '%guid%', либо делать это поле массивом (например, в PostgreSQL поддержаны массивы uuid[]).
А как теперь найти какой-либо адрес в нормализованной части БД? А нужно его пропустить через этот же механизм, получив значения AddressDbRecord, и уже по ним формировать условие where для запроса. Например, если самый низкоуровневый элемент в нём дом, и он привязался к ГАР как guid, то условие будет and HOUSE_GUID='guid' или and 'guid' = any(HOUSE_GUID) в случае массива. Такой запрос захватит и адреса с таким домом и, возможно, разными квартирами, и если нужно убрать из результата квартиры, то добавить условие and LEVEL=8. Если же к ГАР элемент не привязался, то запрос идёт по поисковой мнемонике (и типе), при этом нужно добавить также и условие на родителя, которые если без привязки к ГАР, то и на его родителя и т.д. вплоть до страны. Например, пусть улица привязалась к ГАР, а дом нет, тогда and STREET_GUID='guid' and HOUSE_MNEM='mnem', то есть улицу по guid-у, а дом по мнемонике. Если же и улица не привязалась, а населённый пункт да, то условие дополнится and LOCATION_GUID='guid' and ... и т.д.
Для поддержки формирования SQL при работе с этой структурой можно использовать класс SqlAddressHelper. В нём можно переопределить значения имён полей вышеуказанных элементов (если задать null, то поле не будет формироваться), но можно использовать и предлагаемые. Функция GenerateWhereEqual сгенерирует where-условия SQL для поиска эквивалентного адреса. Данный класс пока на стадии разработки, будем добавлять сюда функции по мере их появления в реальном проекте.